
2024 is AMD's Year. Here's Why.
In this newsletter issue we share our thesis and price target for AMD in 2024.


In this newsletter issue we share our full thesis on AMD for 2024. Our price target is $300 for next year. With the stock at $146 right now, that’s over a 100% gain in one year. We think that this is very doable with the majority of the growth being driven by AMD’s new MI300X AI chip. Read on to find out why and how.
High level questions we’ll answer:
What is AMD’s main source of growth potential next year? In other words, the crux of the bull case
Why is the MI300X chip so exciting for AMD?
What is the MI300X lacking vs Nvidia’s H100? A close look at crucial software-support for both cards.
Why AMD is not as far behind Nvidia as it appears at face value
Why TSMC’s 2024 production projections is good news for AMD
How did we determine the $300 price target?
🆕 Feb 28th, 2024 update
We traded on this idea when we published this newsletter issue in late December and bought a large chunk of AMD calls expiring around its Q4 earnings call (late January).
This trade performed spectacularly and we netted a cool $129,473.88.
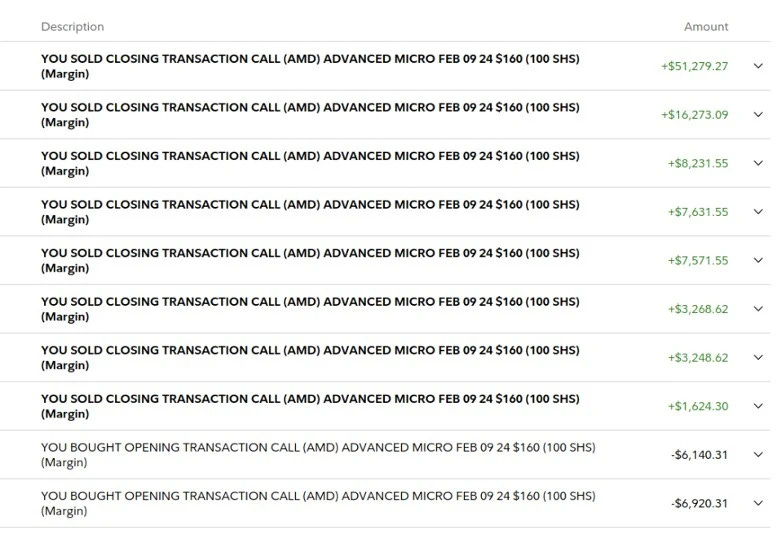
This was a spectacularly profitable idea.
On to the next one!
💡 What is AMD’s main source of growth potential next year? In other words, the crux of the bull case.
The thesis for AMD in 2024 is simple. It’s a year AMD plays significant catch-up with Nvidia in the AI semiconductor market. If you haven’t kept up with the news, this year’s AI boom catapulted Nvidia’s stock price by almost 250% on the backs of rapid revenue and margins expansions.
Why?
Because Nvidia had the best AI GPU on the market and nothing else on the market came close. If you were serious about building an AI business, you needed a fleet of Nvidia’s H100 chips. Large companies and startups were buying H100s by the tens of thousands and Nvidia could hike prices up significantly, resulting in the aforementioned rapid revenue and margins expansions.

AMD, on the other hand, was caught flat-footed by the AI boom and was left out of this year’s massive surge in AI spending. However, through deft and rapid execution throughout this year, we think that AMD has largely bridged its AI technology gap with Nvidia.
In 2024, we expect to see AMD take a meaningful share of Nvidia’s AI business, which would be a boon for its stock price.
Let’s dig into the details.
💡 Why is the MI300X chip so exciting for AMD?
AMD’s answer to Nvidia’s market-dominating H100 GPU is the MI300X.
Announced in June and launched in December, the MI300X is on par with the H100 for AI model training and 10-20% better for AI model inference. Even better, the MI300X is rumored to be significantly cheaper than the H100, coming in at two thirds the price of the latter ($20k vs $30k).

That sounds too good to be true, what’s the catch?
For one, production for the MI300X just started and production capacity has to ramp up first before revenue. Second, software support for the MI300X is considerably behind software support for Nvidia’s H100. Without software that’s optimized for the hardware, hardware performance is meaningless. More on this below.
💡 What is the MI300X lacking (vs Nvidia’s H100)?
As mentioned above, even if the hardware achieves performance parity, it doesn’t matter unless the software controlling the hardware also achieves performance parity.
The software for Nvidia’s GPUs is called CUDA and has been out on the market for almost two decades now. CUDA is practically synonymous with GPU programming. If you’ve ever tried to create a GPU program, you almost certainly had to learn CUDA. As such, CUDA is highly optimized for Nvidia’s GPUs and has industry-wide adoption.
Many have come to refer to Nvidia’s CUDA ecosystem as a walled garden. It’s a closed source project that cannot be adapted to work with anything besides Nvidia’s GPUs.
☕ If you’ve found our work helpful or informative, buy us a coffee by upgrading to a paid subscription. Also get access to the FinanceTLDR portfolio and our trade ideas. Thank you!
AMD’s answer to CUDA is an open source project called ROCm. ROCm is a relatively nascent platform (launched in 2016) that has largely been under-invested by AMD until this year. As such, the platform is under-optimized, hard to use, and lacks industry adoption.
This is a significant problem for AMD. If it wants to seriously compete with Nvidia in the AI chips market, its GPUs need world-class software support. Companies won’t buy your chips if they don’t have programmers that can write efficient code for them.
Thankfully, this strategic weakness is not lost on AMD’s leadership team and the company had quickly brought significant resources to bear onto the ROCm project earlier this year, as can be seen in the project’s code frequency chart below.

💡 Why AMD is not as far behind Nvidia as it appears at face value
My favorite part about AMD’s software catch-up strategy is that they aren’t trying to reinvent the wheel with brute force. In other words, they aren’t trying to copy and re-implement CUDA’s ecosystem for ROCm.
Instead, AMD is working with popular machine learning libraries like vLLM and PyTorch to enable the easy translation of existing library code to work with ROCm. This makes it seamless for programmers that are familiar with those libraries to start programming for AMD’s GPUs.
For those interested in the details, ROCm includes a toolset called HIP that can translate CUDA code into ROCm code. This makes it significantly easier to add ROCm support for libraries that were originally written for CUDA.

OpenAI is helping AMD with Project Triton
Fortunately for AMD, the rest of the industry also sorely wants a competitor to Nvidia and its CUDA walled garden.
OpenAI, for example, has been heavily investing in Project Triton. Triton is a promising high-level GPU programming language that theoretically enables programmers to write code for any GPU architecture without learning their specifics (e.g. CUDA or ROCm).
This chips away at CUDA’s walled garden as GPU programmers don’t have to choose between CUDA or ROCm when growing their programming expertise (the answer is usually CUDA); they could just learn Triton and be an expert in both.
To this end, AMD has been closely collaborating with OpenAI to improve Triton’s support for ROCm.
AMD doesn’t need to get to parity with CUDA
One other key advantage for AMD in its race to catch up to CUDA is that ROCm doesn’t need to reach full parity with CUDA. Business-wise, ROCm just needs to support the deep learning operations that’re required to train and run the LLMs (Large Language Model) driving all the AI hype right now.
This is sufficient for the MI300X to pull substantial demand from the H100 and it’s a much smaller task than getting to fully parity with CUDA.
It’s interesting to note that in the online discourse surrounding CUDA vs ROCm programming, you’ll often find developers complaining about working with ROCm. However, these are usually hobbyist developers that are building “edge case” programs which require a much larger set of GPU operations. Unlike hobbyist developers, AI companies aren’t trying to get their graphics cards to do gymnastics, they only need a limited set of deep learning operations and the rest of their technical problems lie in scaling.

Even though it’s important for ROCm to eventually win over hobbyist developers, from a strictly business perspective, it’s sufficient for ROCm to just have cutting-edge support for deep learning.
Egg on Nvidia’s face
After AMD’s MI300X launch event in early December, Nvidia published a blog post claiming that AMD’s benchmarks were wrong and the MI300X was actually inferior to the H100.
It turns out, Nvidia was too eager to call foul and within 24 hours, AMD fired back with its own blog post to refute Nvidia’s criticisms. Harking back to our point on ROCm optimization being of utmost importance for the MI300X, the post’s authors noted that ROCm had seen significant performance improvements since the original benchmark.
“We are at a stage in our product ramp where we are consistently identifying new paths to unlock performance with our ROCM software and AMD Instinct MI300 accelerators. The data that was presented in our launch event was recorded in November. We have made a lot of progress since we recorded data in November that we used at our launch event and are delighted to share our latest results highlighting these gains.”
Without delving into the details, the general consensus is that AMD won and Nvidia walked away with egg on its face.
If anything, this amusing public debacle between the two corporate giants is further evidence that the MI300X isn’t just a hyped up sales pitch, its packed with real firepower to compete with the H100.
The MI400X will be even better
The MI300X doesn’t exactly have an AI-first design since its platform was originally conceived for HP’s El Capitan supercomputer. This added design constraints to the platform to accommodate for High Performance Computing (HPC) that hampers its ability for AI compute.
Specifically, HPC requires transistors for FP64 operations while AI compute requires transistors for mixed precision.
Expect the next generation of the MI300, the MI400, to have an AI-first design which implies a significant step-up in performance from its predecessor.
💡 Why TSMC’s 2024 production projections is good news for AMD
Taiwan-based TSMC is the sole manufacturer of Nvidia and AMD’s most advanced chips.
Digitimes reported in August that TSMC is planning to double its chip-on-wafer-on-substrate (CoWoS) packaging capacity by the end of 2024. CoWoS packaging is crucial to the production of both Nvidia and AMD’s GPUs.
TSMC is highly optimistic about the demand for the MI300X and expects the chip’s CoWoS capacity to reach half of Nvidia’s capacity by the end of 2024. That’s a huge one-year leap in production capacity for a newly launched GPU!
What does TSMC know that we don’t?
💡 How did we determine the $300 price target?
We believe AMD’s stock can reach this price target through: revenue expansion and price-to-sales multiple expansion.
Not surprisingly, we expect a large chunk of this revenue expansion to come from sales of the MI300X chip. The official sales estimate is $2 billion but this is widely accepted to be highly conservative, I would almost call this sandbagging, and actual estimates on the Street range from $6 to $10 billion. Many of these estimates are derived from TSMC’s CoWoS capacity expansion plan for 2024.
In short, TSMC plans to increase CoWoS capacity to 16,000 wafers in 2024 and it expects one third of that to go to the MI300X. That’s about 5,300 wafers.
Based on these figures and the MI300X’s structural properties, a Seeking Alpha user calculated that TSMC will produce a minimum of 400,000 MI300X chips in 2024. This estimate takes into account a gradual ramp-up in production throughout the year to 5,300 wafers.
The rumored price tag for the MI300X is $20,000 so with 400,000 chips, that implies $8 billion of revenue from the MI300X for next year.
AMD estimates its 2023 revenue at $22.61 billion. For 2024, let’s assume a conservative zero growth scenario for all other parts of the business and add $8 billion of MI300X revenue and we get a total revenue of $30.61 billion for the year.
Nvidia’s Price-to-Sales ratio is currently 22 while AMD’s is at 10. As AMD’s revenue ramps up throughout 2024 from MI300X sales, the market should assign a higher Price-to-Sales ratio to AMD, something closer to Nvidia’s.
If we assume AMD’s year-end PS ratio is 15, then we reach our price target of ~$300 ($145 * 30.61/22.61 * 15/10).
This is a very rough estimation but it’s predicting the future after all and there’s no need to be too precise.
The two Seeking Alpha comments that try to calculate MI300X production based on TSMC CoWoS capacity:
Original: https://seekingalpha.com/article/4640182-ai-gpu-market-disruptor-how-amd-mi300-change-game#comment-96340677
Update: https://seekingalpha.com/news/4044031-amd-takes-wraps-off-nvidia-competitor-updates-ai-forecast?source=content_type%3Areact%7Cfirst_level_url%3Aauthor%7Cbutton%3Aview_comment#comment-96742671
TLDR: base case is 400k MI300X's produced but possibly higher.
I would also add AMD's investment and lead in chiplet technology for its GPUs.
Chiplets have higher yield and lower manufacturing cost, better heat dissipation, more flexibility and scalability and if designed well, doesn't reduce connectivity.
MI300X is chiplet based while H100 and H200 is still monolithic. Nvidia is working on Blackwell, which is chiplets but not sure when they can productionize it.